Best AI evals products for self-hosted / on-prem enterprise deployments (2026)
Self-hosted AI evaluation platforms run on your own infrastructure, allowing enterprise teams to test, score, and monitor LLM outputs without moving sensitive data outside their environment. The best self-hosted eval tools support compliance, trace logging, and release control while keeping operational overhead low. Braintrust combines hybrid and fully self-hosted deployments with production trace-to-eval workflows, AI-assisted scorer generation, and release gating, making it the strongest choice for teams that need self-hosted evaluation directly tied to production.
What is a self-hosted AI evals platform?
A self-hosted AI evaluation platform lets engineering teams test, score, and monitor LLM outputs while keeping prompts, completions, traces, datasets, and evaluation results on their own infrastructure. Self-hosted deployment can mean running in a private VPC on AWS, GCP, or Azure, deploying in an on-premises data center, or operating in an air-gapped environment with no internet access. Teams define quality criteria, run automated and manual evaluations, and track quality over time, all within the organization's network perimeter.
Why enterprise teams need self-hosted AI evaluation platforms
For enterprise teams, the decision to use a self-hosted AI evaluation platform usually comes down to a few practical requirements, including the following.
Data residency and regulatory compliance. Industries like healthcare, finance, and government operate under strict rules about where data can live and who can access it. Prompts, traces, retrieval results, and evaluation data can all fall under data residency, security, and access control requirements. Running an AI evaluation platform within your VPC or another controlled environment gives teams direct control over data residency and access, rather than relying on an external SaaS vendor.
Full visibility into agent workflows. Modern AI applications often follow multi-step workflows in which an LLM retrieves documents, invokes tools, and makes decisions at multiple intermediate steps. Evaluating multi-step AI workflows requires detailed trace logging, not just inspection of the final output. A self-hosted platform lets teams capture and review complete execution data without exposing proprietary logic or customer data outside the organization's environment.
Audit trails and access controls. Enterprise security teams need a record of who ran evaluations, who viewed traces, and when prompts or datasets changed. Role-based access control at the project and resource levels, combined with audit logs, provides compliance and security teams with the documentation they need for internal reviews and external audits.
6 best self-hosted AI evals tools in 2026
1. Braintrust
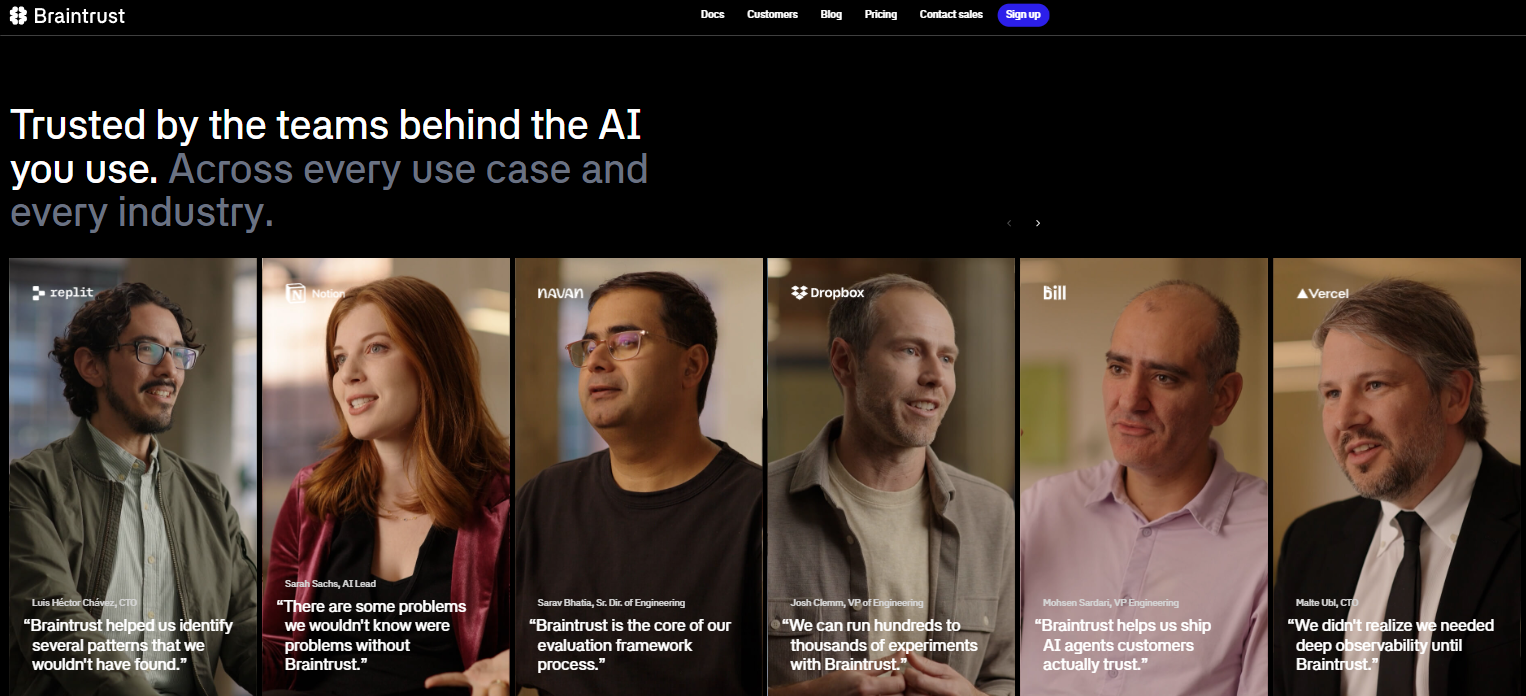
Best for: Enterprise teams that need production-grade evaluation, observability, and experimentation on a single platform, with hybrid or fully self-hosted deployments.
Braintrust provides end-to-end AI evaluation and observability for enterprise teams shipping LLM features to production. Braintrust connects every stage of the AI development lifecycle, from logging production traces to running evaluations in CI to reviewing outputs with human annotators, inside one interface that both engineers and non-technical team members can use.
Self-hosted deployment
Braintrust offers a hybrid deployment model that separates the control plane from the data plane. The control plane handles the UI, metadata, and authentication, while the data plane stores traces, datasets, prompts, and evaluation results. Enterprise customers run the data plane inside their own AWS, GCP, or Azure VPC using official Terraform modules, while Braintrust manages the UI and platform updates. SDKs and the browser UI communicate directly with the customer's data plane, so customer data does not pass through Braintrust's servers.
For organizations that require full isolation, Braintrust also offers a fully self-hosted deployment on the Enterprise plan. Both deployment models support private network access to internal models and databases, firewall and VPN configurations, and configurable data retention policies.
Compliance and security
Braintrust is SOC 2 Type II-certified, HIPAA and GDPR-compliant, and available with Business Associate Agreements. Data is encrypted at rest with AES-256 and in transit with TLS 1.2, and API keys are stored as one-way cryptographic hashes. Braintrust supports enterprise SSO through Okta, Microsoft Entra ID, Google Workspace, and custom OIDC providers. RBAC can be applied at the organizational, project, and object levels, allowing teams to separate sensitive production data from development environments.
Evaluation, experimentation, and collaboration
Braintrust supports LLM-based, code-based, and human scoring through AutoEvals, with built-in scorers for factuality, relevance, security, and other custom criteria. The Playground lets engineers and product managers test prompts, compare models, edit scorers, and review outputs side by side in the browser without writing code.
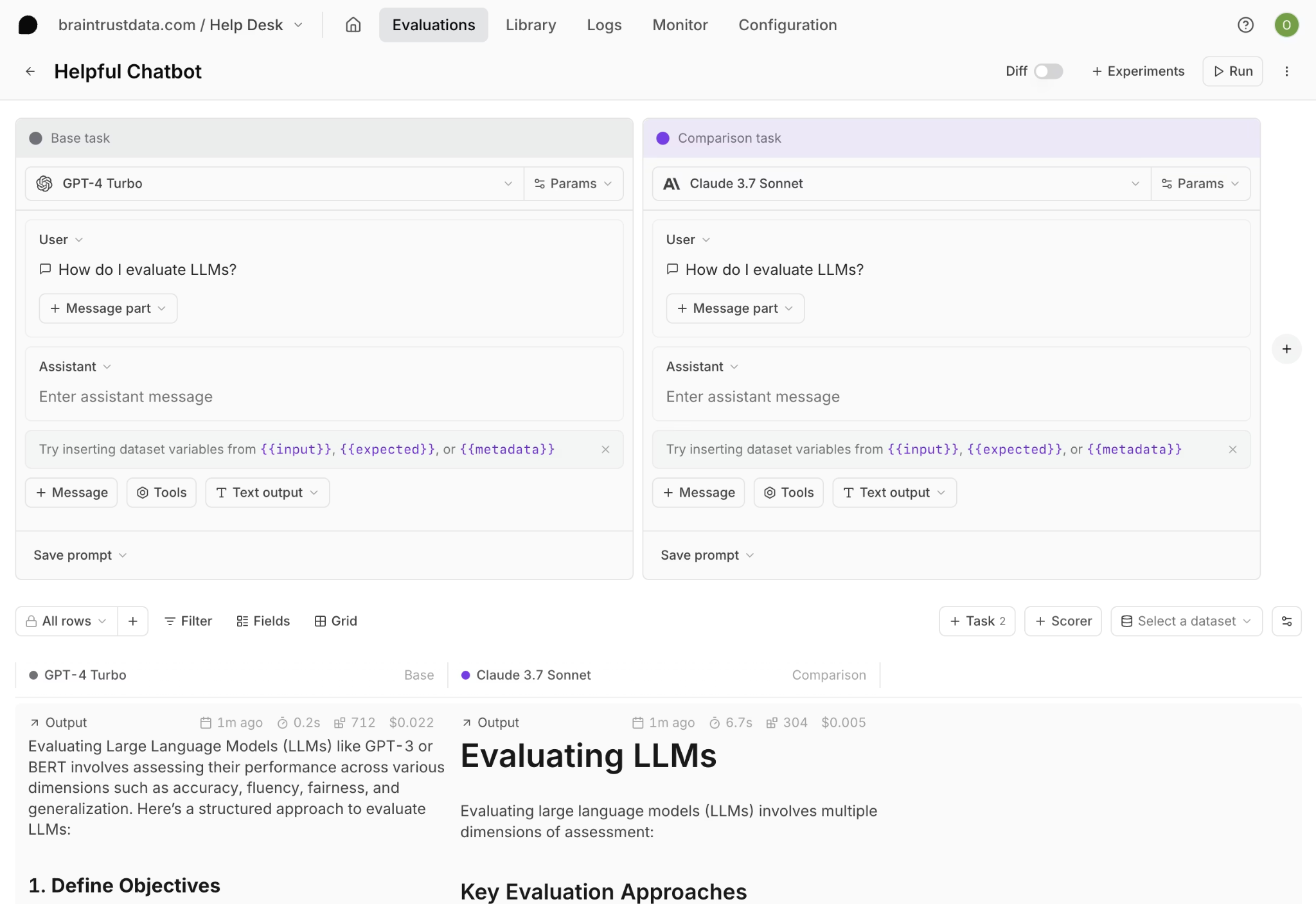
Loop, Braintrust's AI agent, helps teams generate prompts, scorers, and datasets from plain-language instructions. Instead of writing evaluation logic from scratch, teams can describe what they want to measure and use Loop to create scorer drafts and evaluation assets more quickly. Loop can also analyze production logs to identify failure patterns, which makes it useful for cross-functional teams involved in quality improvement.
CI/CD integration
Braintrust includes a native GitHub Action that runs evaluation suites on pull requests and posts the results directly in the PR. Engineers see exactly how a prompt or model change affects output quality before merging, turning evaluation into an automated quality gate inside the release process.
Trace logging and observability
Braintrust automatically captures advanced traces for every logged LLM call, including duration, time to first token, token usage, tool calls, errors, and estimated cost. Brainstore, Braintrust's storage layer for AI observability, supports fast search and filtering across large volumes of trace data and is designed for the nested, variable-length structure of AI traces.
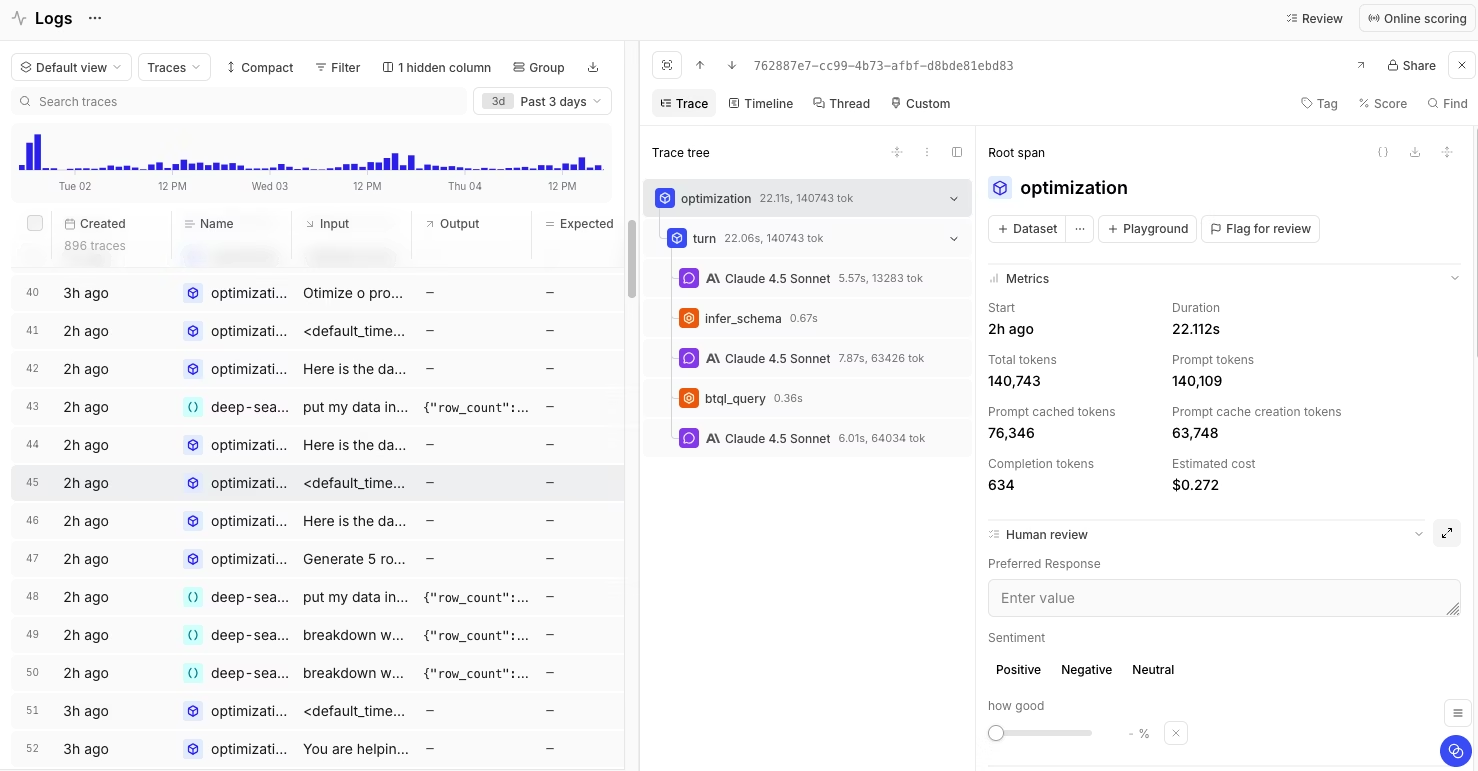
Production traces can also be converted into evaluation datasets with one click. When a failure appears in production, teams can turn that exact scenario into a regression case without exporting data or moving work into another system.
Pros
- SOC 2 Type II, HIPAA compliance, and GDPR compliance, with Business Associate Agreements available and encryption at rest and in transit
- Hybrid and fully self-hosted deployment options, with the data plane running inside the customer's own cloud environment
- Native GitHub Action for PR-level evaluation reporting and release gating
- Loop supports scorer and dataset creation from plain-language instructions, which reduces engineering bottlenecks in evaluation setup
- Playground supports collaborative iteration of prompts, models, and scorers in the browser
- Production traces can be converted into evaluation cases, helping teams increase regression coverage from real failures
- Framework-agnostic SDKs and integrations support a wide range of AI application stacks
- Braintrust Gateway allows teams to route model calls through a single API while keeping logging and observability in sync
- Granular cost analytics help teams understand spend at the request, user, and feature level
Cons
- Proprietary platform with no open-source deployment option
- Self-hosting requires an Enterprise plan
Pricing: Self-hosted deployment is available on the Enterprise plan and includes premium support and SSO/SAML. Teams can evaluate Braintrust first on the Braintrust free tier, which includes 1 GB of processed data, 10K evaluation scores, and unlimited users per month. See full pricing details.
Customers
Notion, Perplexity, Stripe, Vercel, Airtable, Instacart, Zapier, Ramp, Coursera, and other top organizations run production evaluation workflows through Braintrust.
Ready to evaluate Braintrust for your enterprise? Start free or schedule a demo to see how hybrid deployment works in your environment.
2. Langfuse
Best for: Developers who want an open-source, self-hosted LLM observability and evals platform.
Langfuse is an open-source LLM observability and evaluation platform that covers tracing, prompt management, evaluation, and analytics. Engineering teams can self-host the entire system using Docker or Kubernetes at no software licensing cost, or use the managed cloud offering.
Pros
- Open-source core with no feature gates on self-hosted deployment
- Native OpenTelemetry support for piping traces into existing observability infrastructure
- Unlimited users on all plans, with transparent usage-based pricing instead of per-seat fees
- Available on AWS Marketplace for simplified enterprise procurement
Cons
- Self-hosted FOSS version does not include SOC 2 or ISO 27001 certification, so those compliance guarantees only apply to the managed cloud offering
- Production self-hosting requires managing ClickHouse, Redis, PostgreSQL, and S3 infrastructure components, adding significant operational overhead
- No native CI/CD GitHub Action for automated evaluation on pull requests, so teams must build custom pipelines
- Enterprise features like SSO (Okta) and advanced RBAC require a paid license key for self-hosted deployments
Pricing: Free self-hosting and a free cloud plan with 50K units per month. Paid plan starts at $29 per month.
3. Arize Phoenix
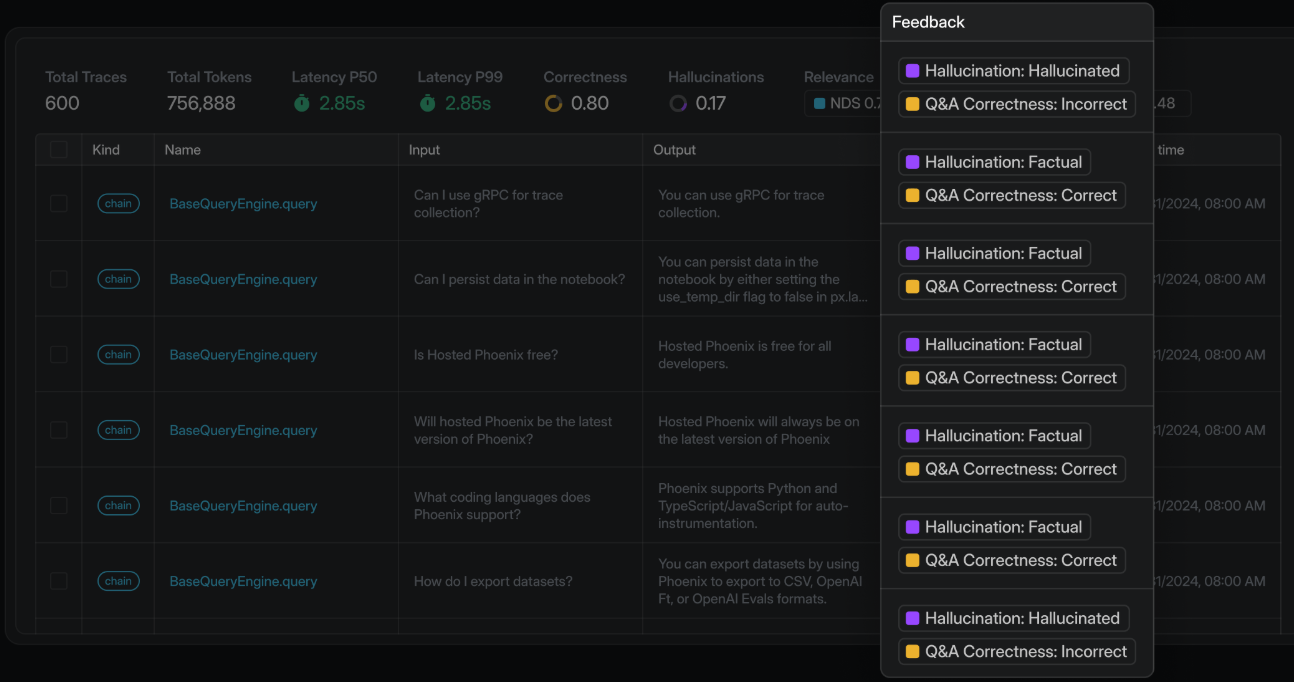
Best for: Engineers who want open-source observability and evals built on OpenTelemetry and OpenInference.
Arize Phoenix is an open-source AI observability and evaluation platform maintained by Arize AI, supporting tracing, LLM-as-a-judge evaluation, code-based metrics, prompt and dataset management, and experimentation. Phoenix can run locally, in Docker, on Kubernetes, or in a free cloud instance. For enterprises that need on-premises deployment with dedicated support, compliance coverage, and SLAs, Arize offers the commercial Arize AX platform.
Pros
- Free self-hosting with no feature gates
- Built on OpenTelemetry and OpenInference, which helps teams keep instrumentation portable
- Supports multiple self-hosting paths, including Docker and Kubernetes
- Enterprise self-hosted support is available through Arize AX
Cons
- Phoenix OSS does not carry SOC 2, HIPAA, or GDPR certifications, so compliance requires upgrading to Arize AX
- Self-hosting Phoenix requires Docker and Kubernetes expertise
- CI/CD integration requires writing custom Python scripts and GitHub Actions workflows instead of a pre-built action
Pricing: Free for open-source self-hosting. Managed cloud at $50/month. Custom enterprise pricing.
4. DeepEval
Best for: Python-native teams that want a code-first evals framework for local and CI-based testing.
DeepEval is an open-source LLM evaluation framework designed for Python teams that want to run evals locally or in CI. DeepEval is positioned as a pytest-style framework for testing LLM applications and includes built-in metrics such as hallucination, answer relevancy, and task-oriented evaluation. For centralized test management, observability, collaboration, and self-hosted enterprise deployment, Confident AI is the commercial platform built on top of DeepEval.
Pros
- Open-source framework for local and CI-based LLM evaluation
- Fits naturally into pytest-style workflows
- Includes a broad set of built-in metrics for LLM testing
- Confident AI adds centralized observability, collaboration, and analytics
Cons
- Production observability, shared dashboards, or trace logging require Confident AI's paid platform
- Confident AI's self-hosted deployment is only available on the Enterprise plan
- The open-source framework is Python-first, which limits its fit for non-Python teams
- No prompt management, prompt versioning, or playground capabilities within the open-source tool
Pricing: DeepEval is free and open-source. Free Confident AI plan with basic features limited to 2 users and 1 project. The paid plan starts at $19.99 per user per month. Self-hosted enterprise plan is custom.
5. Promptfoo
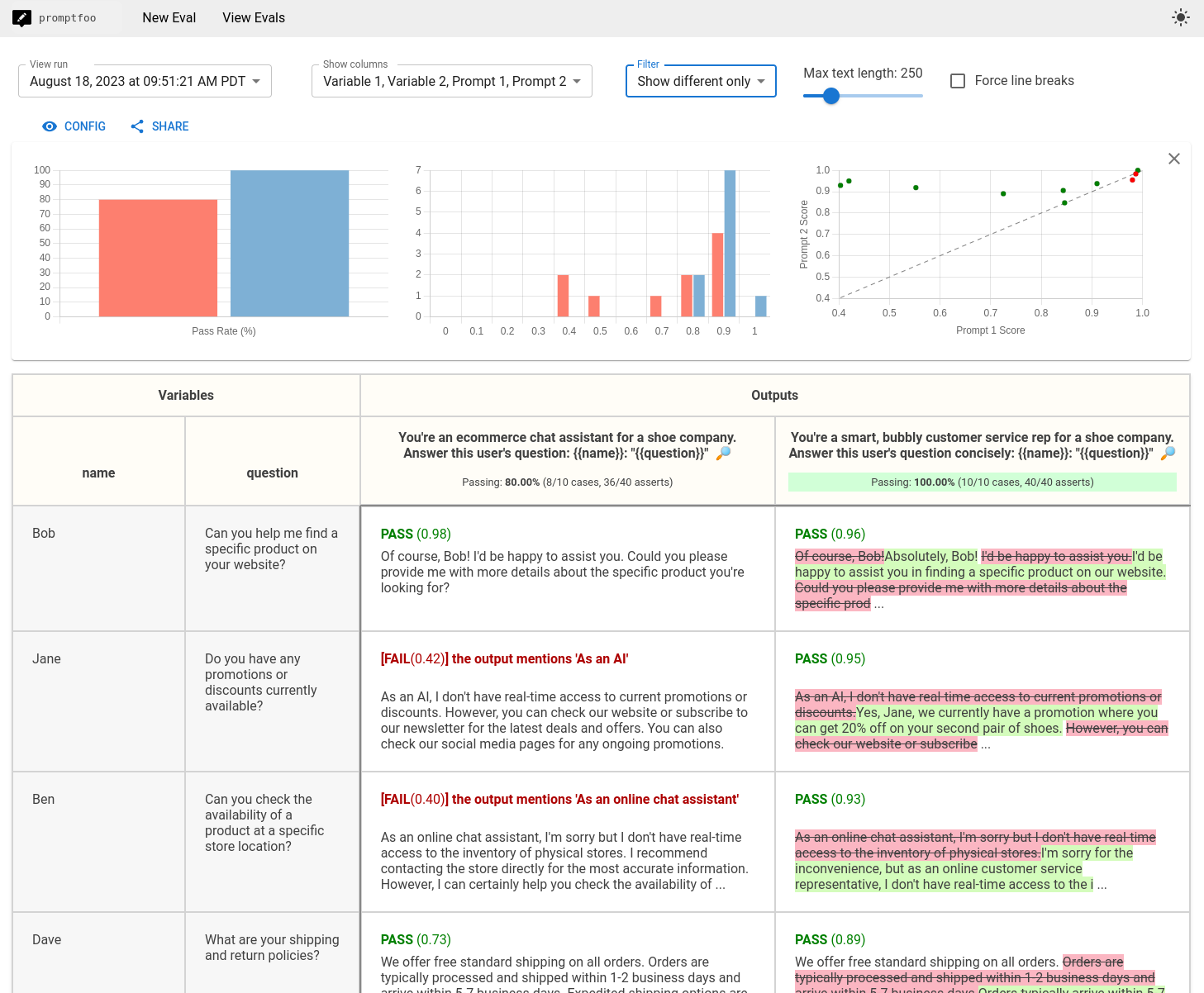
Best for: Developers and small teams that want local prompt testing and red teaming.
Promptfoo is an open-source CLI for evaluating, comparing, and red teaming LLM applications. Promptfoo runs locally and uses declarative test configuration, which makes it useful for pre-deployment prompt testing and security checks.
Pros
- Open-source CLI for local evals and red teaming
- Strong fit for pre-deployment prompt testing and regression checks
- Supports CI/CD workflows, including GitHub Actions
- Covers a broad range of security and red-team use cases
Cons
- Focused on pre-deployment testing rather than production observability and ongoing evaluation workflows
- No pre-built test scenarios require teams to create all test cases manually
- No shared dashboards or team collaboration features in the open-source version
Pricing: Free tier with unlimited open-source use and up to 10k red-team probes per month. Enterprise pricing is customized based on team size and needs.
6. Fiddler AI
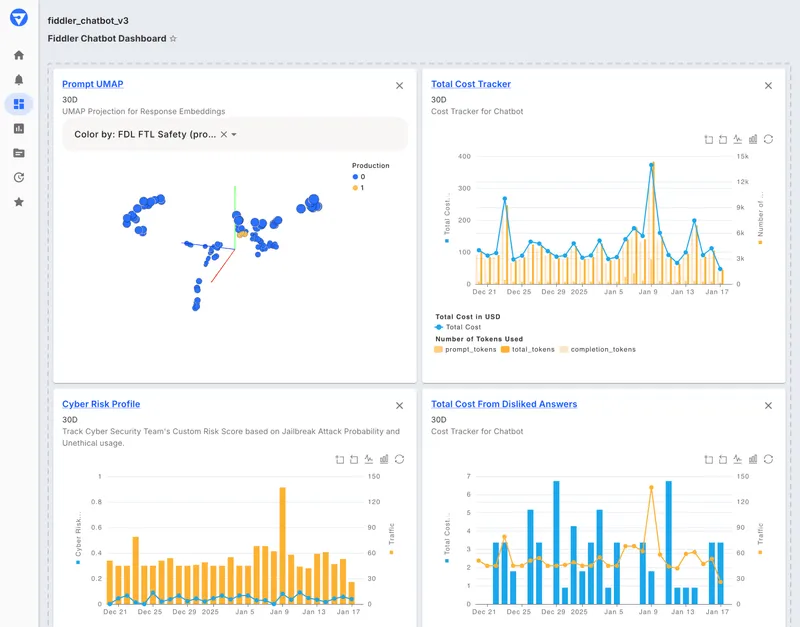
Best for: Regulated enterprises that need broader ML and LLM governance with flexible deployment options.
Fiddler AI is an enterprise AI observability and governance platform for monitoring both traditional ML models and LLM applications. It supports cloud, VPC, on-premises, and air-gapped deployment, with Trust Models that run inside the customer's environment. Fiddler AI is designed for organizations that need compliance, auditability, and oversight across AI systems, especially in regulated environments.
Pros
- Supports cloud, VPC, on-premises, and air-gapped deployment
- Trust Models run inside the customer's environment
- Covers both traditional ML and LLM monitoring
- Supports auditability and compliance review workflows
Cons
- More focused on governance and monitoring than evaluation-driven release workflows
- Less centered on prompt iteration, experimentation, and CI-based quality control
- Better aligned to enterprise oversight than day-to-day eval development
Pricing: Free guardrails plan with limited functionality. Full observability and enterprise deployment require custom pricing.
Comparison table: Best self-hosted AI evals products for enterprises (2026)
| Tool | Self-hosting / enterprise pricing | Best for | Notable features |
|---|---|---|---|
| Braintrust | Self-hosting on Enterprise, custom pricing | Enterprise teams needing eval + observability in one unified platform, with data residency and CI/CD integration | Hybrid/self-hosted deployment (Enterprise); Brainstore for trace storage and querying at scale; Loop AI for automated prompt, scorer, and dataset generation; release gating via native GitHub Action with PR commenting; cross-functional eval UI for engineers and non-technical stakeholders; SOC 2 Type II, HIPAA, GDPR; SSO, RBAC, audit logs |
| Langfuse | OSS self-hosting is free, with custom enterprise pricing | Open-source teams managing their own infrastructure | MIT-licensed; OpenTelemetry support; SOC 2, ISO 27001, HIPAA, GDPR (cloud only; self-hosted OSS carries no formal certs) |
| Arize Phoenix | OSS self-hosting is free, AX enterprise pricing is custom | OpenTelemetry-native teams wanting open-source flexibility | ELv2-licensed OSS; Arize AX for enterprise/on-prem; SOC 2, HIPAA, PCI DSS (Arize AX only -- OSS carries no formal certs) |
| DeepEval | OSS free, enterprise self-hosting custom | Python teams needing pytest-style evals | Built-in metrics library; pytest integration; Confident AI for dashboards and VPC/on-prem hosting (Enterprise only) |
| Promptfoo | OSS is free, enterprise pricing is custom | Developers running local evals and red teaming in CI/CD | Local CLI execution; GitHub Action integration; red-teaming presets; SOC 2 Type II, ISO 27001, HIPAA; on-prem/air-gapped on Enterprise |
| Fiddler AI | Enterprise self-hosting, custom pricing | Regulated enterprises needing ML + LLM governance | Air-gapped and VPC deployment; in-environment scoring models; compliance audit trails; unified ML + LLM observability |
Upgrade your AI evals workflow with Braintrust. Start free today.
How we chose the best self-hosted AI evals tools for enterprise teams
Deployment flexibility. Whether each tool supports VPC deployment, on-premises installation, air-gapped environments, and hybrid deployment models.
Compliance coverage. Whether enterprise certifications such as SOC 2 Type II, HIPAA, GDPR, and ISO 27001 apply to self-hosted deployment, the cloud offering, or both.
Evaluation depth. The range of built-in metrics, support for custom scorers, LLM-as-a-judge scorers, and human review capabilities.
Trace logging and observability. How each tool captures, stores, and queries production trace data, especially for multi-step AI systems with nested workflows.
CI/CD integration. Whether evaluation can run automatically during development through native GitHub Actions, PR-level reporting, and release gating.
RBAC and audit trails. We reviewed whether each tool supports granular access control, project-level isolation, and audit logs that help security and compliance teams review evaluation activity.
Scalability. How well each platform handles production trace volume, including the underlying storage model and query performance at scale.
Why Braintrust leads for enterprise self-hosted evals
Self-hosted deployment addresses data residency, but enterprise teams also need a way to run evaluations and review failures without having to manage the databases, storage, and other infrastructure required to support reliable production. Braintrust is the strongest fit for enterprise teams that need self-hosted evaluation to influence release decisions by connecting production failures to evaluation workflows, allowing teams to turn LLM output failures into regression coverage within a single platform.
Braintrust's hybrid deployment model keeps sensitive data in the customer's environment while reducing operational burden. Enterprise teams at Notion, Stripe, Vercel, Airtable, Instacart, Zapier, Ramp, and Coursera use Braintrust to run end-to-end AI evals workflows.
Braintrust's free tier provides enough capacity to validate the full LLM evaluation workflow before committing to the enterprise plan. Start free today or book a demo to see how hybrid deployment works in your environment.
FAQs: Best self-hosted AI evals platforms for enterprises
What is a self-hosted AI evaluation platform, and why do enterprise teams need one?
A self-hosted AI evaluation platform runs inside your own infrastructure rather than on a vendor's cloud, letting teams test, score, and monitor LLM outputs while keeping all data within their network perimeter. Enterprise teams in regulated industries need self-hosted deployments to meet data residency requirements under frameworks such as HIPAA and SOC 2. Braintrust offers both hybrid and fully self-hosted deployment options that satisfy enterprise requirements while maintaining a managed UI experience.
How do I choose between open-source and commercial self-hosted eval tools?
Open-source tools like Langfuse and Arize Phoenix provide free self-hosting with community support, but enterprise features like SSO, advanced RBAC, and compliance certifications often require a paid license or a separate commercial platform. Managed platforms like Braintrust bundle compliance certifications, enterprise support, and a managed UI into their self-hosted offerings, reducing the operational load on infrastructure teams.
Which is the best self-hosted AI evals platform for enterprise teams?
Braintrust is the strongest option for enterprise teams because it combines evaluation, tracing, and experimentation into a single platform, with SOC 2 Type II and HIPAA compliance built into the self-hosted deployment. The hybrid model keeps all sensitive data in your VPC while Braintrust manages the UI and platform updates, so your team avoids the infrastructure overhead of a fully self-managed stack.
Is Braintrust better than Langfuse for enterprise self-hosted evals?
Langfuse gives teams full control via open-source, but production self-hosting requires managing ClickHouse, Redis, PostgreSQL, and S3, and SOC 2 certification applies only to the managed cloud version of Langfuse.
Braintrust's hybrid model handles infrastructure management while keeping data in the customer's VPC, and SOC 2 Type II and HIPAA compliance apply to the self-hosted deployment. For enterprise teams that need compliance certifications on the self-hosted version without running their own database stack, Braintrust is the better fit.
What are the best alternatives to LangSmith for self-hosted evals?
For teams that need self-hosted deployment, the main alternatives are Braintrust, Langfuse, Arize Phoenix, and DeepEval. Braintrust is the strongest option for enterprise teams that want self-hosted evaluation connected to production workflows and release control. Langfuse and Arize Phoenix are the main open-source options for teams that prefer to manage their own infrastructure, while DeepEval is a stronger fit for Python teams that want a local evaluation framework for CI.