Evals are the new PRD
Traditional product development follows a well-worn loop.

This works when output is deterministic. Write a spec, build to spec, verify against spec. But AI output is non-deterministic. The same prompt produces different results every time. A spec that says "the model should be helpful and concise" is too vague to be actionable, too ambiguous to verify, and too static to keep up with a system that changes behavior with every model update.
PRDs were designed for a world where you could fully specify the desired behavior of a system upfront. AI products don't work that way, and the question for product managers is what replaces the PRD. The answer is evals.
The new product development loop
For AI products, a better development loop looks like this.
The PM defines what "good" looks like through structured, repeatable tests. The eval becomes the spec, the acceptance criteria, and the roadmap all at once. It defines the target, measures pass or fail, and shows where to improve next. The team then hillclimbs against that target: the PM sets the bar in evals, and the team iterates on prompts, retrieval, tools, models, and system design until the product clears the quality bar.
As Kevin Weil, CPO at OpenAI, put it, "Writing evals is the most important thing a PM can do in the AI era." This is a fundamental shift in how product managers operate. You define measurable signals that verify desired behavior.
What an eval actually is
An eval is a structured, repeatable test that answers one question. Does my AI system do the right thing? Think of it as a unit test for AI behavior. You define a set of inputs along with expected outputs, run them through your AI system, and score the results using algorithms or AI judges. For a deeper dive into the mechanics of building evals, datasets, scorers, and experiments, Evals for PMs: A practical guide to AI product quality covers that ground in detail. This post is about why evals should replace your PRD and how that changes the PM role.
Translating PRDs into evals
Every section of a traditional PRD has a direct analog in the eval world.
| PRD concept | Eval equivalent |
|---|---|
| Functional requirements | Test scenarios with inputs and expected outputs |
| Acceptance criteria | Eval rubrics for accuracy, tone, safety, and other dimensions |
| Roadmap priority | Regression thresholds that define minimum quality bars |
| ROI model | Eval score to business metric correlation |
| Launch readiness review | Automated eval gates in CI/CD |
The difference is that every row in the eval version is measurable, automated, and runs continuously. A PRD gathers dust in a Google Doc. An eval suite runs on every commit.
A concrete example
Say you're building a recipe generation feature from cooking videos. The PRD says "be helpful and accurate." What does that actually mean?
Break it into three measurable signals.
Is the recipe formatted correctly? Ingredients should come first, then steps. An AI judge can evaluate structural formatting against a rubric.
Are all video-mentioned ingredients included? This is a deterministic check. A string match algorithm can verify that every ingredient mentioned in the video transcript appears in the generated recipe.
Are instructions written in short, scannable sentences? Another AI judge, calibrated against examples of good and bad instructional writing.
That gives you three measurable signals and one hill to climb. Instead of telling engineering to "make it better," you hand them an eval and say "make this number go up."
The flywheel matters more than the first eval
Writing your first eval is straightforward. The hard part is building the flywheel, a tight loop between production data and eval quality that compounds over time. The teams that win with AI are the ones that have built this loop, and it has four stages.
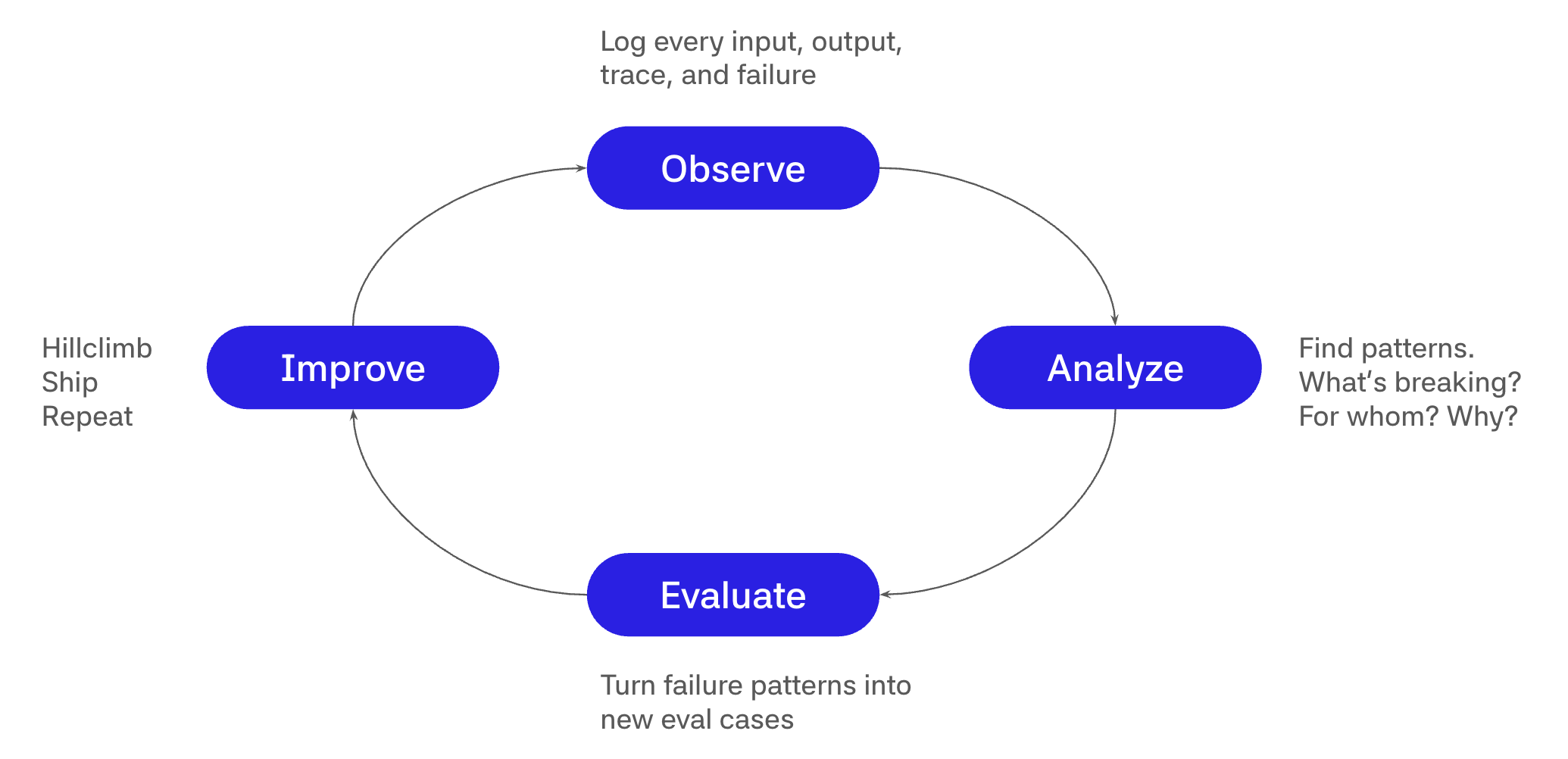
First, observe by logging every input, output, trace, and failure so you have full visibility into what your system is doing in production. Then analyze to find patterns. What's breaking, for whom, and why? This is where observability turns into product intelligence. Next, evaluate by turning those failure patterns into new eval cases, because every production failure is a candidate for your eval suite. Finally, improve by hillclimbing against your updated eval suite, shipping the improvement, and repeating.
This cycle accelerates over time. More production data feeds better evals, which drive better AI, which creates a better product, which attracts more people and generates more production data.
Flywheel maturity stages
Most teams progress through four stages of eval maturity. At stage 0, you're relying on vibes. Manual spot-checks, intuition, and complaints from the field. There's no structured measurement and you're flying blind.
Stage 1 is where most teams land first. You have test sets with pass/fail criteria that run on demand, usually before a major release. This is a significant improvement over vibes, but it's still reactive.
At stage 2, evals become automated and integrated into CI/CD. Bad releases get blocked before they reach production and quality is enforced systematically.
Stage 3 is the flywheel, where production data continuously flows back into your eval suite. The system gets better every week because real-world failures become new test cases automatically. This is the stage that compounds into a durable advantage, and it's where most teams should be aiming.
What fuels the flywheel
You can't improve what you can't see. The flywheel runs on observability, and observability for AI products goes beyond traditional monitoring. You need full trace logging that captures every step from input through tool calls through generation through the end user's reaction. You need semantic quality signals beyond latency and error rates, because your definition of "good" matters more than your p99. You need the ability to search, filter, and curate production failures quickly. And you need a fast path from "this response was bad" to "here's a new eval case," because the shorter that path, the faster your flywheel spins.
Three types of eval judges
Different eval criteria call for different measurement approaches. There are three types of judges, and knowing when to use each one matters.
- Algorithmic judges handle quantitative, deterministic checks like string matching, format validation, and length constraints. These are fast, cheap, and perfectly reliable.
- AI judges handle fuzzy quality assessments where you have clear golden examples, evaluating subjective dimensions like tone, helpfulness, and coherence. They scale instantly but require calibration against human judgment to be trustworthy.
- AI judges with human alignment handle deeply subjective evaluations where human review provides the ground truth and the AI judge learns to approximate it. These are deceptively hard to get right, but they're the only way to handle complex quality dimensions where reasonable people might disagree.
Common mistakes
A few patterns reliably derail eval programs. The first is trying to measure "general intelligence" instead of focusing on the specific tasks your product needs to perform well. General benchmarks won't tell you if your recipe generator produces scannable instructions.
Another common trap is involving too many stakeholders in eval design. More voices lead to compromise-driven, unfocused evals, so keep the design team small and opinionated. Similarly, trusting third-party evals without verification is risky. Always inspect a sample of results, because an eval you haven't validated is just someone else's vibes.
Teams also tend to run evals only at launch and then stop. Evals that don't run continuously are a one-time sanity check, not a quality system. Models change, data drifts, and edge cases accumulate. Finally, watch out for optimizing eval scores instead of real outcomes. Goodhart's Law applies here. If you optimize purely for the metric, you'll game it. Keep tying eval scores back to real outcomes like task completion, satisfaction, and retention.
The PM's new job description
The AI PM's job is to define what "good" looks like in code, curate the data that reveals what "bad" looks like, own the flywheel that turns bad into good into better, and protect the product against regression as models change. The directive to engineering is simple. "Here is the eval. Make this number go up."
In practice, this translates to a weekly cadence.
Monday. Review production traces. Flag 20 responses that missed the mark.
Tuesday. Curate those 20 into 5 new eval cases. Add them to the eval suite.
Wednesday. Run the full eval suite against last week's model and this week's candidate.
Thursday. Review the delta. Ship or don't. The data decides.
Friday. The flywheel just got faster.
The signal hiding in your product
Every interaction with your AI product is a signal. A thumbs-down can become a new eval case. An edited output can serve as ground truth. A copy-paste followed by task completion can indicate success. A person rephrasing the same prompt three times may reveal an eval gap.
Product usage is a continuous source of quality signal. With the right observability, teams can capture those signals, turn them into better evals, and use them to improve the system over time.
The only question that matters
For an AI product, the most important question is simple. Is the product getting better?
That is why evals replace the traditional PRD. They specify desired behavior, define acceptance criteria, track progress, and prevent regression in a form that works for non-deterministic systems. Unlike a document, they run automatically, continuously, and on every commit.
That creates the flywheel. Product usage generates signals, observability captures them, evals turn them into targets, and the team improves the system against them.
If you're an AI PM still writing traditional PRDs, start with one feature, define three measurable signals, and build your first eval. Then build from there. That's the job now.
Trace everything
Create an account or use agent setup to start building today.